Private Cloud- An insight
Introduction
Servers (at the application level) were now just like any other application, this gave the ability to run multiple applications as servers on a single hardware. This also made the servers portable, i.e. one can install and run it on any physical machine. So application becomes totally independent of the physical server and operating system. The operating system was still more or less attached to the physical server. With hypervisors gaining popularity, stability and plumbing cost of physical hardware (value of software is much bigger than hardware now), the age of virtualization was set.
Below is the chronology of events/ disruptions that changed the way infrastructure is managed in enterprises.
Year
|
Event
|
2003
|
VMware launched VMware Virtual Center, the VMotion, and Virtual SMP technology
|
2006
|
Amazon launched AWS as public cloud service
|
2010
|
OpenStack launched as open source platform to deploy public and private cloud
|
Cloud offers three distinct services to consumers, SaaS, PaaS, and IaaS
SaaS: Software as service, don’t install software on your local machine, but use it remotely.
PaaS: Platform as service as the name suggests, environment to develop and host your applications on remote machines.
IaaS: Infrastructure as service, create infrastructure and build your own environment bottom up. Create compute (virtual machines), with storage and required networking.
This paper will focus on IaaS deployment and delivery in detail. Paper will also cover operational aspects of behind the scene IaaS.
A Bare Metal Server
What is a bare metal server? This phrase is used very frequently in cloud computing world. Is it a computer machine in some metal chassis, with multiple ports and cavities staring at one’s face? Answer it is relative, or in simple words, any machine whether it is virtual or physical where one can install an operating system is a bare metal server. So a physical machine is indeed a bare metal but a virtual blank machine is also a bare metal.
Logically computer requires following three things to work as a generic all-purpose machine.
- 1 Processor & RAM for computation and volatile storage (compute)
- 2 Storage for recording data and files for long-term purpose (Disk, File Systems, and Files)
- Network to connect and talk to other devices
So logically if one can make available these three entities working together, we can have a computer machine. That’s what the role of hypervisors is, they create virtual representations of these three units on the top of underlying hardware to create a brand new computer. Now to use this machine, one need to install an operating system on it.
 |
| components of virtual machine |
Virtual Machine & Environment
As discussed above virtual machine is a bare metal server. One can install the operating system and run their applications on it. So instead of putting a large number of physical boxes and cramming up space, one has the option to put the relatively bigger box and logically allocating resources from combined pool. Since virtualized machines behave like a physical machine there is great isolation that prevents conflicts between different users.
With isolation, there is one additional benefit of dispensability. Virtual machines can be shut down thrown away, recreated any number of times. If designed properly and data files are well separated from operating system files, these machines can be turned off on one physical machine and turned on at any other physical machine. Multiple instances of the same operating system and therefore application can be run like one can open multiple browsers on their desktops or laptops.
Virtual machines – What can be achieved
Virtualization opens doors for better asset management and application lifecycle control. Below are the salient features of virtualization.
- Virtual machines run on top of hypervisor software, all popular hypervisors come with a user interface (a.k.a managers) to create, manage and migrate virtual machines.
- Hypervisor managers don’t work across different hypervisor types. E.g. one cannot control KVM hypervisor with VMware.
- Some managers provide automation module, to automatically schedule many provisioning jobs.
- In a well-designed virtual machine operating system files will remain totally isolated from the application and user data files. This gives the advantage to spin up new VM’s and move VM around different physical machines.
- More virtual machines can be created out of available resources rather than starting a grounds up procurement procedure as done with physical machines.
- Making infrastructure available for end users is fast.
- The network can be defined by the hypervisor software. It can be altered, augmented without any wiring or physical changes, given underlying physical infrastructure is set up in the correct manner ( a spine-leaf type of wiring for Ethernet).
- The hypervisor can be used to provide switching, routing and DHCP functions to configure networks.
- Load balancing concept can also be virtualized
- So there are many salient features that are present in a virtualized environment. But there are some issues with this approach, however, this approach is better than legacy infrastructure setup in every manner.
- One issue in this approach is vendor lockdown. One has to choose the appropriate underlying operating system (for hosting type 2 hypervisor) and the hypervisor and then live with it. Once an environment is created and scaled in production, users are left with the very little choice to change the components.
- If one mixes different hypervisors in their environment, there will be interoperability issues as managers do not cross function.
- Management through this will not be effective on very large scale.
So as we can see we can achieve a lot with virtualization but it falls behind in a certain aspect. This, however, does not suggest that virtualization should not be used, or some other solution can replace hypervisor-based virtual environments for a better layout in totality.
Virtualization has a great advantage over the legacy environment, where applications were hosted on the physical servers directly. In past, the virtualization concept was tried from a different viewpoint (Zones and Vtier concept on Solaris environment), but implementation required a lot of policy enforcement at people level as Zones and Vtier concept does not provide a desirable level of isolation out of the box.
Virtual machines – Virtual Network
Hypervisors act as switch and router for virtual machines created on them, let’s take all the use cases of networking that arise from virtualization.
Standalone Virtual Machine
In this mode, a machine is created, but it’s not connected to any network. It’s like having a machine without any network card. This setup is of practically no use, but for learning only. One can access this machine only through management console of host machine.
 |
| standalone VM without networking |
Configuration with NAT (Network Address Translation)
Every standard libvirt installation provides NAT based connectivity to virtual machines out of the box. This is the so-called 'default virtual network'.
One can define their own IP network (given example uses 1922.168.122.0/24). Host machine uses libvirt to forward traffic from VM to external LAN/ WAN. No one can reach the VM’s as the example network (192.168.122.0/24) is invisible from LAN. However one can use port forwarding on the host machine to VM to reach it from the external network. A new interface is created on the host machine by the name of virbr0.
The salient feature of this setup is it’s security as it is isolated from the external world.
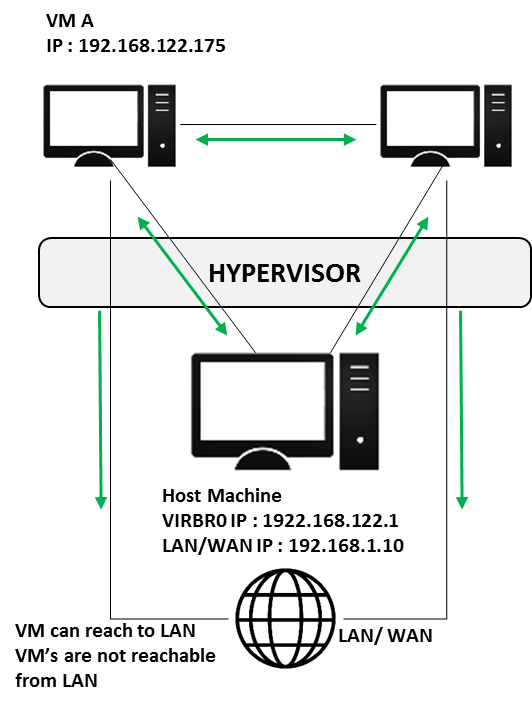 |
| Natted VM on Host |
|
|
Configuration with MACVTAP
Macvtap driver (verified on KVM) extends an existing network interface, host machine has its own mac address on the same Ethernet segment. Typically, this is used to make both the guest and the host show up directly on the switch that the host is connected to. An experimental setup results in the following connectivity.
As you can see in the given setup there is no MACVTAP IP assigned to host machine, VM’s and Host cannot connect to each other. But since they are directly connected to LAN, communication can happen from VM to LAN and another way round. However, being on same network segment VM’s and host cannot talk even using LAN switch (L2), as switching relies on frames rather than IP address. In given situation switch understands underlay network setup only, it considers packets originating from VM-A, VM-B and Host machine from the same source as MAC address appears same to it.
To conquer this situation we need a bridge between MACVTAP and Host LAN/ WAN interface.
|
| MACVTAP VM configuration |
Using Bridge Connection
This solution requires creating a bridge on the host machine and attaching the LAN interface to the bridge. The Later same bridge is plugged into VM as Ethernet interface. This creates an internal routing mechanism and every node is now connected to main LAN/ WAN with two-way traffic.
The connectivity on example setup looks like below.
VM-A can talk to VM-B using bridge interface at the host to route their packets. Bridge interface can also forward and receive packets from LAN/ WAN on behalf of VM’s and itself.
This scheme is good where one needs full connectivity, but it is weak on security if used as it is. There is no isolation on VM from LAN/ WAN.
 |
| VM and Host attached to Bridge Interface |
Virtual machines – Storage
A computer requires a secondary storage to retain its files. Without secondary storage, computer cannot even boot, as there will be no operating system to load. Secondary storage can be local in the form of a local disk device or can be remote (in this case computer can boot using PXE routines).
As with all other aspects of computing, it is possible to virtualize storage. Virtualization creates a layer of abstraction between the underlying hardware and the virtual system, so heterogeneous physical storage media can be combined to create a homogeneous storage pool. Virtual machines have the privilege to define virtual disks (this disk just become a file on the main disk). However, a physical disk can also be assigned as a whole to a virtual machine. A computer needs OS kernel to boot and device drivers to load and control devices. With Linux, it is very handy to separate storage devices for boot sequence (OS image files) and user data/ files. There are two primary forms of virtual storage, ephemeral storage, and persistent storage. Ephemeral Storage
Ephemeral storage is the default form of storage for most virtualization platforms. The defining characteristic of ephemeral storage is its inability to survive virtual machine termination. Within that constraint, there are two forms of ephemeral storage, boot-ephemeral storage, and boot-persistent storage.
Boot-Ephemeral Storage
Boot-ephemeral storage is a storage volume attached to the virtual machine. These volumes are usually attached in read-write mode, so they are capable of performing useful storage functions. However, they are destroyed when the virtual machine is shut down, and are re-instantiated when the virtual machine is booted. Boot-Ephemeral volumes present an empty storage space on every boot.
Boot-Persistent Storage
Boot-persistent storage is a form of ephemeral storage capable of surviving virtual machine shutdown. This form is commonly used as the root disk for a given virtual machine. Boot-persistent ephemeral storage is not generally used for other attached disks. Data saved to boot-persistent volumes will be available on the next machine reboot. However, one the virtual machine is deleted from the hypervisor, any boot-persistent volumes will be deleted as well.
Persistent Storage
Persistent storage is capable of preserving data across multiple machine creation and deletion. This type of storage is typically block-level storage and emulates a classic hard drive. Persistent volumes can be used in the same way as any physical hard drive. They can be mounted, unmounted, written and read. Persistent volumes can, therefore, be used as root disks, allowing custom virtual machines to be created and deleted as needed while preserving customization.
Cloud Computing
“The practice of using a network of remote servers hosted on the Internet to store, manage, and process data, rather than a local server or a personal computer.”
The scope of computing covers following three aspects depending what one requires as described above in introduction sections of this document.
Virtualization provides a lot of flexibility, as it exposes commands/ API’s which can be envoked via scripts. This opens up numerous opportunities to use virtualization to achieve much easier management of day to day operations. This flexibility allows IT operations (especially Infrastructure management services group) to lower its turnaround time to make IT infrastructure ready for business. Following are salient features of cloud computing.
There are a ton of other benefits that come from virtualization when this scheme is bundled as a managed software. Like these benefits were presented as a complete product suite by VMware as private cloud and AWS (Amazon web services) as public cloud. There are some other ways by which cloud form can be achieved within an organization, but all this require a management layer which is as complex as the operating system. Private Cloud – Assumptions & Myth
When IT transforms from legacy model to cloud model, there are a lot of assumptions among IT and business people. This confusion is obvious as cloud literacy is lacking among IT and business people likewise. Following are some assumptions that are prevalent among IT people.
Myth: Every application from legacy world need to move on cloud
Every application need not be on a cloud environment. Cloud provides some distinct capabilities and if applications do not require those capabilities or do not have compatible architecture, they need not move to Cloud environment. However, every application can be moved to the virtual machine.
Myth: Virtualization and Cloud are same.
No, they are not. Virtualization is a necessary ingredient of cloud, but in itself, it is not cloud. Cloud is an ecosystem built on top of virtualization. It provides all the functions of virtualization over a (very large) aggregation of machines distributed over geography. It also provides several other facilities and utilities as building blocks for applications. Many aspects like in and out scaling, high availability are out of box solutions available on cloud ecosystems.
Remember Cloud operating system are different than normal operating system images. Cloud images boot non-interactively or silently (it will not ask you for username, password, disk format etc.). Normal OS when installed requires many inputs from admins at install time. So if organizations start using virtualization it does not means they are fully ready for transition into a cloud environment. Public Cloud: Ease of doing business
There are many public cloud providers in the market today, providing cloud facilitates over the Internet. Giants like Amazon, Google, Redhat, Rackspace etc.. provide very mature and end to end well-integrated platforms to host and create your applications.
Let’s take an overview of AWS (Amazon Web Services) and see what can be achieved on a cloud.
The above screenshot is taken on (2/2/2017) and shows latest offerings to the mentioned date. AWS provides services in all three flavors (IaaS, PaaS, and SaaS).
Suppose yourself as a business owner selling some merchandise. You have stores in many locations and you have decided to start selling online too. What you need, to begin with?
The answer may be following:
Now you can use either IaaS or PaaS services to create your new business.
In IaaS model you can get EC2 instances (virtual machines with full network and public facing addresses) and install your application, related software like Tomcat and database. You will have a lot of control over your environment in this case. Remember with more power comes more responsibility.
In PaaS model, you can leverage services provided out of the box by AWS and start running your business. E.g. you can rent database instead of renting an EC2 instance and install it yourself. This will cost you more in AWS bills but will you will not be required to maintain a database (activities like backup, expand, failover etc.) yourself.
A middle path is also available when you use a blend of IaaS and PaaS. Thus let’s assume you rent EC2 servers for hosting application and middleware but use an Amazon provided database instead of using your own.
After some time you see that your online store is working very well. A lot of people are visiting your store and demand is growing. You also notice that sometimes application is responding slowly. This means you need to increase server capacity by either adding more resources to your existing servers (increasing CPU and memory) or add more servers. Since its cloud auto scale is part of the package, you just need to decide when. If you know the timelines it well and good, but if you are unsure it’s better to make it event based.
Thus you may require some monitoring tool. AWS has one which comes out of the box called CloudWatch. It will trigger event to add or remove additional computation power from your portfolio. You can add additional alerts to be emailed to you in case you some problem happens by using AWS notification service SNS.
One day you receive an email from SNS that out 500 GB space you started with 450 GB is used. When you check you find that log files are taking too much space. You have two options now.
1Let’s assume you choose S3 options. One day you realize that there is a lot you can do with dormant data you threw in S3 chest. If you could mine this data you can get valuable input to optimize and grow your online business.
Again AWS platform can help you. There are again some options that you need to choose from. Options may be as follows:
This mentioned use case is very limited and shows reactionary situations. However, people do and should plan the system well in advance in terms of what they need from the platform.
However AWS platform in the benchmark for private cloud implementations. Most of the questions that originate while deploying private cloud can be answered by looking into AWS model.
Openstack – Operating System for Private Cloud
OpenStack is open source cloud enabling a solution for in premises private cloud or AWS-like public cloud. It is also called operating system of cloud a. In nutshell one can manage a large set of hardware with this solution (hardware resources appear as pool). OpenStack is the open source community managed software, with many leading open source vendors providing different support and subscription model.
At very high-level OpenStack can be broken down into three main components. Controller
As the name sounds this is command center of OpenStack deployment. Multiple utilities make the controller. The objective of the controller, is to control all other hardware in the given deployment through its agents (Nova, Swift, Cinder and Neutron) to create VM’s, storage, file systems and networks on demand.
The controller may be one node, server or bare-metal (in the modern terminology). However, it is not necessary to pack all the following software on one node. This software can be distributed among various nodes to create distributed controller. Following is the easiest and straightforward configuration. In a single OpenStack cloud deployment, there may be more than one controller for failover purpose. Following is the list of software that should be part of controller (The list may vary by implementations/ versions)
ComputeCompute is the bare metal server, on which one will create end user VM’s (will also be referred as workloads). Compute will have OpenStack components to talk back to the controller and carve out VM with required CPU, memory, storage and networking. These nodes will require following components on them.
StorageThere are two types of storage that are required to create and maintain end user workloads.Object StorageObject storage is required to store OS image files, backups and snapshots and make them available to end user on demand. OpenStack by default uses swift object storage (there are many backend object storage solutions that can be used, like CEPH from a red hat).Use case: Store centos operating system image and show its availability to end user on Horizon dashboard with its metadata (like architecture type, minimum hardware requirements) Solution: Upload the image to either local (in /var/lib/glance/ images on the controller or any node where Glance server resides) or on backend storage system like CEPH or swift for high availability. OpenStack provides Swift object storage solution out of the box. To configure a bare metal with object store, we need to run following services on the given node.
Block StorageBlock storage is an allocation of raw storage to VM. Block storage is also known as Volume in OpenStack environment. Volumes can be attached to any VM as persistent storage. So if one kills a VM, deletes it, migrates it, the volume will remain persistent and can be reattached to a VM. Think volume as a USB drive which you can plugin into any computer.Cinder is the OpenStack component which needs to be installed on any bare metal with a proper operating system where one need to configure block storage. Volumes in Cinder are managed using an iSCSI (Internet Small Computer System Interface) and LVM (Linux logical volume manager). LVM is volume management technology that is used by Cinder. LVM has a lot of advantages, listed below.
Following software is required on block storage node.
(Illustration on next page shows minimal requirements to run Openstack cloud, this is not production grade and should be used towards building test or lab environments)
Openstack – Network Requirements
As seen above OpenStack
is the big complex system. It requires a
lot of components to run together for creating a cloud environment for end-user workloads (a.k.a VM). Since VM’s will
have their own business related traffic, sharing same network resources with
data spitting OpenStack components is not
a good idea.
Business traffic may consume network bandwidth to choke OpenStack components and may result in the
downfall of Cloud. On the other hand, OpenStack may also consume too much bandwidth
for business traffic to suffer. So OpenStack
has distinct network requirements, to separate business traffic and OpenStack management traffic.
(Below illustration shows minimal network requirements)
However, some scheme
may use 3 network options (will require additional network cards on storage
nodes) to further bifurcate OpenStack
traffic into regular and storage networks.
The figure below
illustrates an example multi-site reference of the Openstack cloud. We will use this network diagram as a reference for some use cases to discuss and
understand the concept of cells, availability zones,
and multi-site cloud. Here in this figure,
there are two OpenStack clouds on LHS (left-hand side) and RHS (right-hand side), connected over WAN (wide area
network). There are VM’s (VM-1, VM-2, VM-3,
and VM-4) created over two sides and are connected to WAN.
We are putting a lot of emphasis on networking model of
different use cases because networking is
one of the most crucial aspects of
virtualization and cloud services.
OpenStack and network layers
This is popular OSI model for network beginners. OpenStack networks revolve mostly around Data Link layer (switches or Layer2 or L2)
and Network layer (routers or Layer 3 or L3). As its clear, it OSI model, all the layers above Physical Layer (L1) are a
just abstraction. Two machines connected
with wire or wireless connection need to configure all above abstractions
properly to create a proper communication
channel, which is called “Network” in common language.
OSI model supports virtualization from its inception. OpenStack or any other virtualization
technology reuses age old network architecture to recreate overlays over
existing physical network.
Openstack Network Example
This section talks about OpenStack
tenant networks. These networks are meant
for internal connectivity between workloads (VM’s) and external connectivity on
different corporate networks depending on requirements.
In the given example “private” network with subnet
“private-subnet” is default network available to VM’s that are created. Network “internet” is a corporate network which can be accessed over
the internet. Network “ext-net is a corporate network for private LAN.
So VM’s can be created using any network. A VM can be
created as isolated node using the private
network and provided access to external users using floating IP’s from either
or both of two external networks. A VM can also be created directly using
either or both of external networks (a.k.a provider networks)
The below figure illustrates how a VM is created with a private network and how the connectivity with
external networks happen. Note how different subnets are in place, packets in
one subnet can reach the other destination as it uses L2 layer of OSI model.
When packets are interchanged between subnets as happening with two routers we
have in this scheme, an L3 layer of OSI
model is used. Note this L2 and L3 communication channels are supported by OpenStack, when the VM’s are residing on the single physical node.
Since control plane is nothing but a software entity which
can be deployed on some remote simple computer, VM’s become choice of host for
this software. Interestingly the control plane can also be used to manage the
vSwitches (virtual switches) and vRouters (virtual routers). In nutshell,
dissociation of control plane and data plane paves the way of SDN (software-defined networking).
OpenStack can be configured to work with third party vRouter and
vSwitch, depending on requirement. However, neutron provides many rich
functions for L2 and L3 out of the box.
Openstack – Operations Management
OpenStack is meant to
scale, that means the creation of a cloud
that spawns across datacenters and geographies. But before going there, we need
to understand following aspects of cloud usage from OpenStack perspective.
Private cloud can be broadly classified into two major teams
in the terms of management.
This structure looks similar to what we have and had for
years in traditional IT environment. Infrastructure teams were people whom we
called system/ network administrators and IT teams used to engage them on need
basis. In private cloud the broad classification remains some but some more
responsibilities got added on both ends to make overall IT more responsive and
robust.
In principle both need not to know about each other on
day-to-day operations basis. Both teams have very well defined roles with clear
segregated duties. They must nor play in each other’s domain to keep things
well managed and tidy.
However despite all the care, design and thought meeting
this objective is very tough, but all energies must be diverted in this
direction.
Let’s discuss about the roles and responsibilities of both
team and their segregation of duties.
Like any other software,
Openstack needs to be.
OpenStack makes the
grass on business side green but it comes with its own complexity for
infrastructure support groups (Server administrators, data center architects
and designers and Network teams).
Openstack – Infrastructure Teams
Openstack infrastructure teams can now further be subdivided
into two further teams:
Monitoring
OpenStack components
need to be monitored using different monitoring tools. OpenStack needs multiple services to run simultaneously to execute
user workload requests. Monitoring the crucial services becomes essential for
the smooth working of the cloud.
The aspect of monitoring covered in this document only
pertains to bare metal and process related to OpenStack.
This document does not talk about workload monitoring.
OpenStack need following
aspects to be monitored.
Most of the monitoring tools need their own data storage
systems and tenants may also use same installation of monitoring tools to
monitor their workloads. This makes to organizations choose one of following
models.
Let’s see how the
network configuration will look in both scenarios.
v
In above deployment, tool infrastructure (agent-master mode,
or agentless) is put on the cloud. Both
physical layer and workloads are using cloud deployment.
This deployment uses a model where tools of physical layer
are hosted on physical infrastructure (may be reusing the controller nodes
themselves).
|











Comments
Post a Comment